3.4. scikit-learn: Pythonで機械学習¶
著者: Gael Varoquaux
参考
Pythonでデータサイエンス
Pythonで統計 の章は、機械学習を研究している読者にとっても興味深いものでしょう。
documentation of scikit-learn は非常に完成度が高く、教訓的です。
3.4.1. はじめに: 問題設定¶
3.4.1.1. 機械学習とは何か?¶
Tip
機械学習とは、 調整可能なパラメータ を持つプログラムを構築することであり、そのプログラムは、 過去に見たデータに適応することによって 、動作を改善するように自動的に調整されます。
機械学習は、 人工知能 のサブフィールドと考えることができます。なぜなら、これらのアルゴリズムは、データベースシステムが行うようなデータ項目の保存と検索を行うだけでなく、何らかの方法で 一般化 することによって、より知的な振る舞いをコンピュータに学習させるためのビルディングブロックと考えることができるからです。
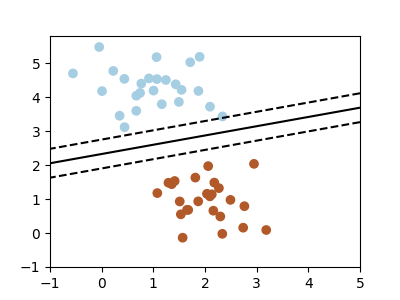
分類問題¶
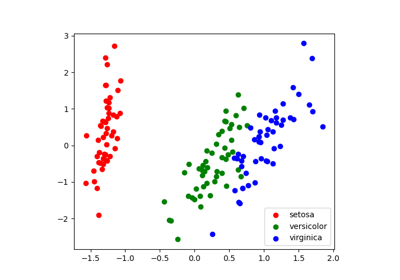
ここでは2つの非常に単純な機械学習タスクを見てみましょう。 1つ目は、 分類 タスクです: 図は、2つの異なるクラスラベルに従って色分けされた2次元データの集合を示しています。 分類アルゴリズムは、2つの点のクラスター間の境界線を引くために使うことができます:
この分離線を引くことで、新しいデータに 汎化 できるモデルを学習したことになります: もしラベルのない平面に別の点を落とすとしたら、このアルゴリズムはその点が青か赤かを 予測 することができます。
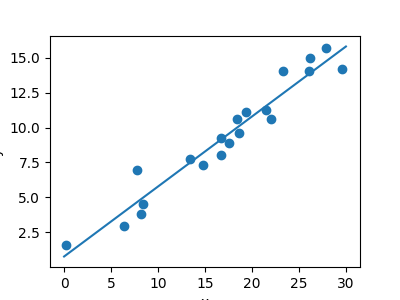
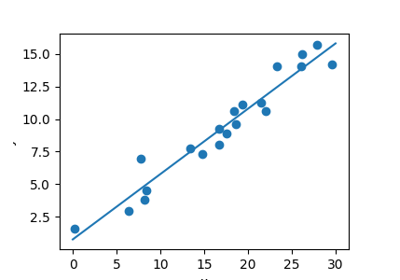
回帰問題¶
次の簡単なタスクは、 回帰 タスクです: データ集合の単純なベストフィットの直線。
繰り返しますが、これはモデルをデータに当てはめる例ですが、ここでの焦点は、モデルが新しいデータについて一般化を行うことができるということです。 モデルは学習データから 学習 され、テストデータの結果を予測するために使われます: ここでは、x値が与えられ、モデルによってy値を予測することができます。
3.4.1.2. scikit-learnのデータ¶
データマトリックス¶
scikit-learnで実装されている機械学習アルゴリズムは、データが 2次元の配列または行列 に格納されていることを期待します。 配列は numpy 配列か、場合によっては scipy.sparse 行列です。配列のサイズは [n_samples, n_features] となります。
n_samples: サンプルの数: 各サンプルは、 (分類などの) 処理をする項目です。 サンプルは、文書、画像、サウンド、ビデオ、天体、データベースやCSVファイルの行、または定量的な特徴の固定セットで記述できるものであれば何でもかまいません。
n_features: 各項目を定量的に記述するために使用できる特徴または明確な形質の数。 特徴は一般に実数値ですが、場合によってはブーリアン値や離散値であることもあります。
Tip
特徴の数はあらかじめ決まっていなければなりません。 しかし、それは非常に高次元 (例えば数百万の特徴量) である可能性があり、与えられたサンプルに対してそのほとんどがゼロである可能性があります。 このような場合に scipy.sparse 行列が役に立ちます。これは、NumPyの配列よりもはるかにメモリ効率がよいからです。
簡単な例: アヤメの花データセット¶
アプリケーションの問題¶
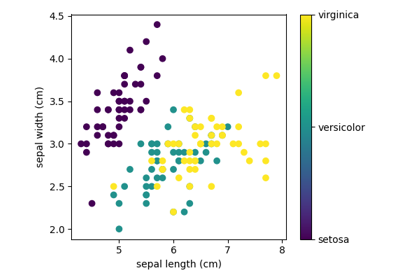
単純なデータセットの例として、 scikit-learn が保存しているアヤメのデータを見てみましょう。アヤメの種類を認識したいとします。データは3つの異なる種類のアヤメの測定値からなります:
|
|
|
|---|---|---|
ヒオウギアヤメ |
ブルーフラッグ |
バージニアアイリス |



各サンプルには 固定 個の特徴がなければならず、特徴番号 i は各サンプルで同種の量でなければならないことを覚えておいてください。
scikit-learnでアヤメの花データを読み込む¶
Scikit-learnには、これらのアヤメの種に関する非常にわかりやすいデータセットがあります。データの構成は以下の通りです:
アヤメの花データセットの特徴:
がく片長さ (cm)
がく片幅 (cm)
花弁の長さ (cm)
花弁の幅 (cm)
予測する対象クラス:
ヒオウギ
ブルーフラッグ
バージニア
scikit-learn は、アヤメのCSVファイルのコピーと、それをNumPyの配列にロードする関数を埋め込んでいます:
>>> from sklearn.datasets import load_iris
>>> iris = load_iris()
注釈
sklearn をインポートします scikit-learnは sklearn としてインポートされることに注意してください。
各サンプルの花の特徴は、データセットの data 属性に格納されます:
>>> print(iris.data.shape)
(150, 4)
>>> n_samples, n_features = iris.data.shape
>>> print(n_samples)
150
>>> print(n_features)
4
>>> print(iris.data[0])
[5.1 3.5 1.4 0.2]
各サンプルのクラスに関する情報は、データセットの target 属性に格納される:
>>> print(iris.target.shape)
(150,)
>>> print(iris.target)
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
クラス名は最後の属性である target_names に格納されます:
>>> print(iris.target_names)
['setosa' 'versicolor' 'virginica']
このデータは4次元ですが、散布図を使って一度に2つの次元を視覚化できます:
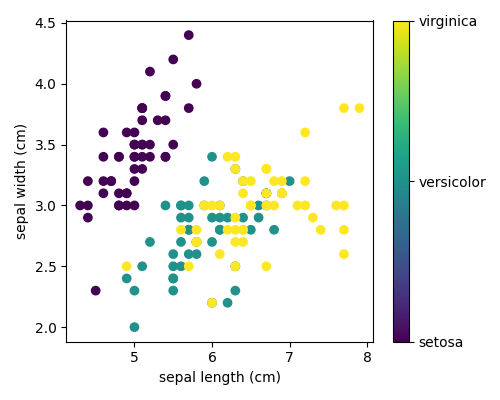
3.4.2. scikit-learnによる機械学習の基本原理¶
3.4.2.1. scikit-learnのestimatorオブジェクトの紹介¶
scikit-learn ではすべてのアルゴリズムが ''Estimator'' オブジェクトを通して公開されます。 例えば線形回帰は次のようになります: sklearn.linear_model.LinearRegression
>>> from sklearn.linear_model import LinearRegression
推定パラメータ: 推定量のすべてのパラメータはインスタンス化時に設定できます:
>>> model = LinearRegression(n_jobs=1)
>>> print(model)
LinearRegression(n_jobs=1)
データへのフィッティング¶
numpy で簡単なデータを作ってみましょう:
>>> import numpy as np
>>> x = np.array([0, 1, 2])
>>> y = np.array([0, 1, 2])
>>> X = x[:, np.newaxis] # The input data for sklearn is 2D: (samples == 3 x features == 1)
>>> X
array([[0],
[1],
[2]])
>>> model.fit(X, y)
LinearRegression(n_jobs=1)
推定パラメータ: データに推定量を当てはめる場合、手元のデータからパラメータが推定されます。推定されたパラメータはすべてestimatorオブジェクトの属性であり、アンダースコアで終わります:
>>> model.coef_
array([1.])
3.4.2.2. 教師あり学習: 分類と回帰¶
教師あり学習 では、特徴量とラベルの両方からなるデータセットがあります。課題は、特徴量の集合が与えられたときに、オブジェクトのラベルを予測できる推定器を構築することです。 比較的単純な例として、アヤメの花の測定値の集合からアヤメの種類を予測することができます。 これは比較的単純な作業です。もっと複雑な例としては:
望遠鏡を通した天体の多色画像が与えられたら、その天体が恒星、クエーサー、銀河のどれであるかを判断する。
人物の写真が与えられたら、写真に写っている人物を特定する。
ある人が観た映画のリストと、その人の個人的な評価が与えられたら、その人が好きそうな映画のリストを推薦する (いわゆる レコメンダーシステム: 有名な例は Netflix Prize) 。
Tip
これらのタスクに共通しているのは、対象物に関連する1つ以上の未知の量があり、それを他の観測された量から決定する必要があるということです。
教師あり学習はさらに、 分類 と 回帰 の2つのカテゴリーに分けられます。分類ではラベルは離散的であり、回帰ではラベルは連続的です。 例えば天文学では、ある物体が星なのか、銀河なのか、クエーサーなのかを判断する作業は、分類の問題です: ラベルは3つのカテゴリーに分かれています。一方、このような観測に基づいて天体の年齢を推定したいと思うかもしれません: これは回帰の問題でしょう, なぜなら、ラベル (年齢) は連続量だからです。
分類: K最近傍(kNN)は最も単純な学習戦略の一つです: 新しい未知の観測が与えられたら、どの観測が最も近い特徴を持っているかを参照データベースで調べ、優勢なクラスを割り当てます。アヤメ分類の問題で試してみましょう:
from sklearn import neighbors, datasets
iris = datasets.load_iris()
X, y = iris.data, iris.target
knn = neighbors.KNeighborsClassifier(n_neighbors=1)
knn.fit(X, y)
# What kind of iris has 3cm x 5cm sepal and 4cm x 2cm petal?
print(iris.target_names[knn.predict([[3, 5, 4, 2]])])
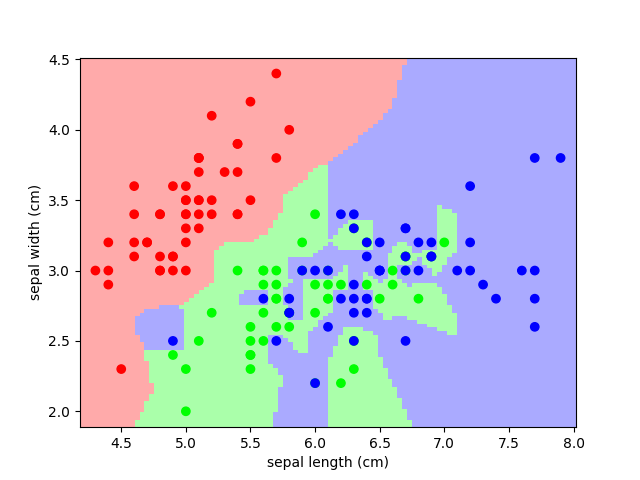
がく片の空間とKNNの予測値のプロット¶
回帰: 最も簡単な回帰設定は線形回帰です:
from sklearn.linear_model import LinearRegression
# x from 0 to 30
rng = np.random.default_rng()
x = 30 * rng.random((20, 1))
# y = a*x + b with noise
y = 0.5 * x + 1.0 + rng.normal(size=x.shape)
# create a linear regression model
model = LinearRegression()
model.fit(x, y)
# predict y from the data
x_new = np.linspace(0, 30, 100)
y_new = model.predict(x_new[:, np.newaxis])
単純な線形回帰のプロット。¶
3.4.2.3. Scikit-learnのestimatorインターフェイスのまとめ¶
Scikit-learn は全てのメソッドで統一されたインターフェイスを持つように努めており、以下にその例を示します。 model という名前の scikit-learn estimator オブジェクトが与えられた場合、以下のメソッドが利用できます:
- すべての Estimator の場合:
model.fit(): トレーニングデータに適合します。教師あり学習アプリケーションでは、データXとラベルyの2つの引数を受け付けます(例model.fit(X, y))。 教師なし学習アプリケーションの場合、引数はデータXだけです(例model.fit(X))。
- 教師あり推定量 の場合:
model.predict(): 訓練済みのモデルが与えられた場合、新しいデータセットのラベルを予測します。このメソッドは1つの引数、新しいデータX_new(例えばmodel.predict(X_new)) を受け取り、配列内の各オブジェクトの学習済みラベルを返します。model.predict_proba(): 分類問題については、いくつかの推定器もこの方法を提供しており、新しい観測値が各カテゴリラベルを持つ確率を返します。この場合、最も確率の高いラベルがmodel.predict()によって返されます。model.score(): 分類や回帰の問題では、ほとんど (すべて?) の推定器がスコア法を実装しています。スコアは0から1の間で、大きいほどフィットしていることを示す。
- 教師なし推定量 の場合:
model.transform(): 教師なしモデルが与えられた場合、新しいデータを新しい基底に変換します。これもX_newを引数にとり、教師なしモデルに基づいたデータの新しい表現を返します。model.fit_transform(): この方法は、同じ入力データに対してフィットと変換をより効率的に実行します。
3.4.2.4. 正則化: 正則化とは何か、なぜ必要なのか¶
シンプルなモデルを好む¶
訓練誤差 1-最近傍推定量を使用しているとします。 訓練セットにはいくつの誤差が予想されますか?
訓練セットの誤差は予測性能の測定には適していません。 テストセットを除外する必要があります。
一般的には、訓練セットの誤差は受け入れるべきです。
正則化の例 正則化の背後にある核となる考え方は、ある ''単純化'' の定義では、たとえ訓練セットでより多くの誤差をもたらすとしても、より単純なモデルを選好するということです。
例として、9次の多項式にノイズを入れて生成してみましょう:
次に、4次と9次の多項式をデータに当てはめてみましょう。
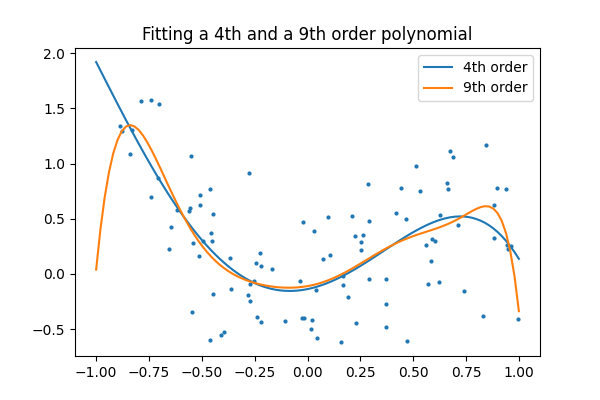
あなたの肉眼では、4次と9次、どちらのモデルが好きですか?
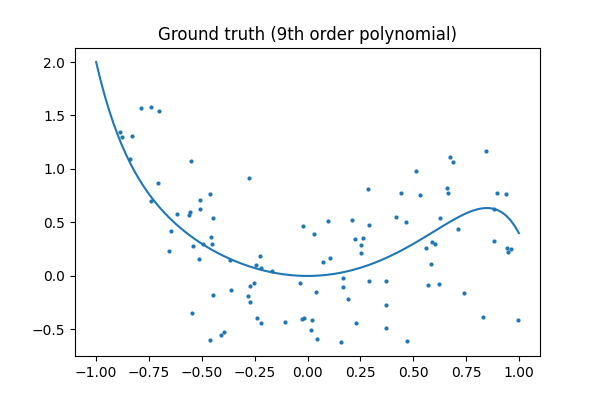
真実を見てみましょう:
Tip
正則化は機械学習ではどこにでもあります。ほとんどのscikit-learnの推定量には、正則化の量を調整するパラメータがあります。例えば k-NN の 場合、 'k' 、つまり判定に使われる最近傍の数です。 k=1 は正則化なし: 学習セットでのエラーは0、一方、kが大きいと、特徴空間内の判定境界が滑らかになります。
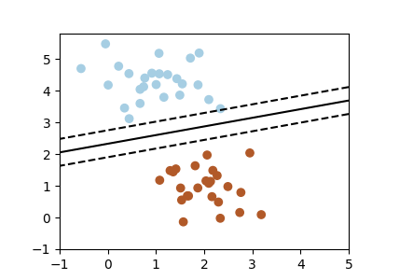
分類のための単純なモデルと複雑なモデル¶
|
|
|---|---|
線形分離 |
非線形分離 |
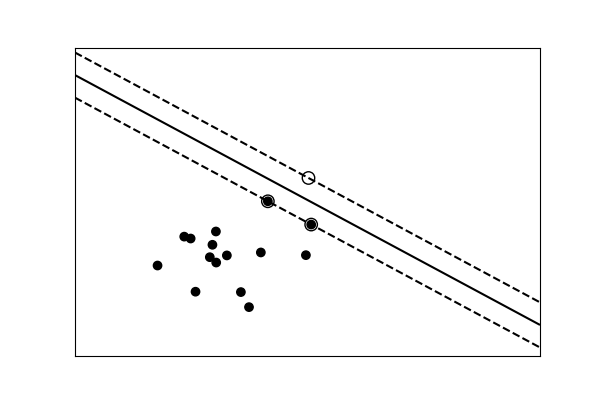
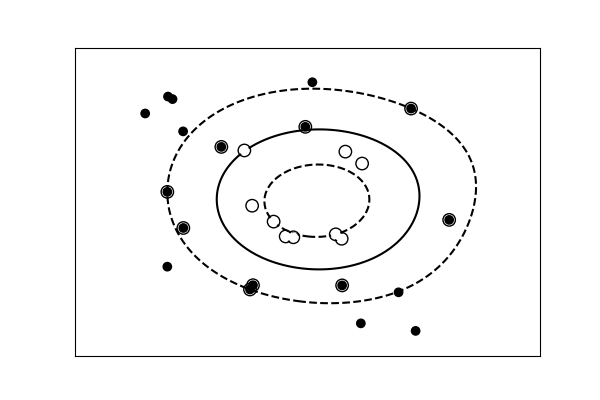
Tip
分類モデルの場合、 クラスを分ける決定境界はモデルの複雑さを表します。 例えば、特徴の線形結合に基づいて決定を下す、線形モデルは非線形モデルよりも複雑です。
3.4.3. 教師あり学習: 手書き文字の分類¶
3.4.3.1. データの性質¶
このセクションでは、手書き数字の分類にscikit-learnを適用します。 これは、以前見た虹彩の分類を少し超えるでしょう: ここでは、分類モデルの有効性を評価するために使用できるメトリクスについて説明します
>>> from sklearn.datasets import load_digits
>>> digits = load_digits()

データを視覚化し、私たちが何を見ているのかを思い出させてくれます (図をクリックするとフルコードが表示されます):
# plot the digits: each image is 8x8 pixels
for i in range(64):
ax = fig.add_subplot(8, 8, i + 1, xticks=[], yticks=[])
ax.imshow(digits.images[i], cmap=plt.cm.binary, interpolation='nearest')
3.4.3.2. 主成分でデータを可視化する¶
多くの問題に対する良い最初のステップは、 次元削減 技術を使ってデータを可視化することである。 まずは一番簡単な Principal Component Analysis (PCA) からです。
PCAは、最大の分散を示す特徴の直交線形結合を求めます、 というように、データセットの構造を知るのに役立ちます
>>> from sklearn.decomposition import PCA
>>> pca = PCA(n_components=2)
>>> proj = pca.fit_transform(digits.data)
>>> plt.scatter(proj[:, 0], proj[:, 1], c=digits.target)
<matplotlib.collections.PathCollection object at ...>
>>> plt.colorbar()
<matplotlib.colorbar.Colorbar object at ...>
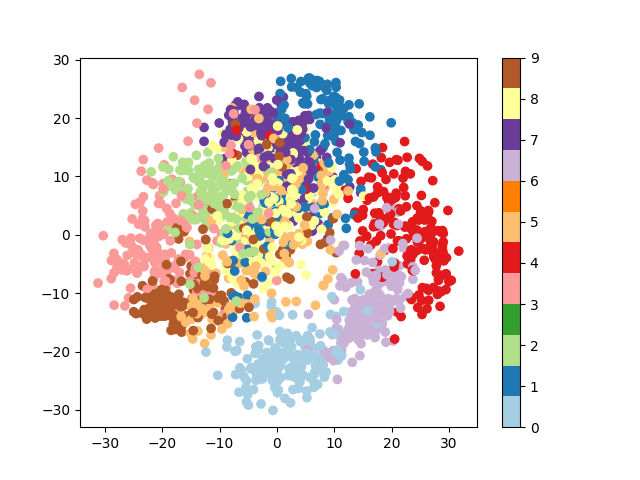
3.4.3.3. Gaussian単純ベイズ分類器¶
ほとんどの分類問題では、ベースライン分類を素早く提供するシンプルで高速な方法があるといいです。シンプルで高速な方法で十分なら、より複雑なモデルでCPUサイクルを浪費する必要はありません。そうでない場合は、単純な方法の結果から、データについての手がかりを得ることができます。
覚えておくといい方法のひとつが Gaussian Naive Bayes (sklearn.naive_bayes.GaussianNB) です。
Tip
Gaussian Naive Bayes は、各特徴について、各学習ラベルにガウス分布を個別に当てはめ、これを用いて素早く大まかな分類を行います。一般的に、実世界のデータに対しては十分な精度が得られませんが、テキストデータなどでは驚くほど高い精度を発揮することがあります。
>>> from sklearn.naive_bayes import GaussianNB
>>> from sklearn.model_selection import train_test_split
>>> # split the data into training and validation sets
>>> X_train, X_test, y_train, y_test = train_test_split(
... digits.data, digits.target, random_state=42)
>>> # train the model
>>> clf = GaussianNB()
>>> clf.fit(X_train, y_train)
GaussianNB()
>>> # use the model to predict the labels of the test data
>>> predicted = clf.predict(X_test)
>>> expected = y_test
>>> print(predicted)
[6 9 3 7 2 2 5 8 5 2 1 1 7 0 4 8 3 7 8 8 4 3 9 7 5 6 3 5 6 3...]
>>> print(expected)
[6 9 3 7 2 1 5 2 5 2 1 9 4 0 4 2 3 7 8 8 4 3 9 7 5 6 3 5 6 3...]
上記のように、予測されたラベルと数字をプロットして、分類がどの程度うまくいっているかを確認します。

3.4.3.4. パフォーマンスの定量的測定¶
例をプロットすることなく、我々の推定器の性能を測定したいです。 単純な方法は、単純にマッチした数を比較することかもしれません:
>>> matches = (predicted == expected)
>>> print(matches.sum())
385
>>> print(len(matches))
450
>>> matches.sum() / float(len(matches))
np.float64(0.8555...)
450の予測の80%以上が入力と一致することがわかります。 しかし、分類器の性能を判断するために使用できる、より洗練された測定基準もあります: sklearn.metrics サブモジュールにいくつか用意されています。
最も有用な測定基準のひとつは classification_report で、これはいくつかの測定基準を組み合わせ、その結果を表にしたものです:
>>> from sklearn import metrics
>>> print(metrics.classification_report(expected, predicted))
precision recall f1-score support
0 1.00 0.95 0.98 43
1 0.85 0.78 0.82 37
2 0.85 0.61 0.71 38
3 0.97 0.83 0.89 46
4 0.98 0.84 0.90 55
5 0.90 0.95 0.93 59
6 0.90 0.96 0.92 45
7 0.71 0.98 0.82 41
8 0.60 0.89 0.72 38
9 0.90 0.73 0.80 48
accuracy 0.86 450
macro avg 0.87 0.85 0.85 450
weighted avg 0.88 0.86 0.86 450
この種のマルチラベル分類のためのもう1つの啓発的な指標は、 混同行列 です: これは、分類エラーでどのラベルが入れ替わっているかを視覚化するのに役立ちます:
>>> print(metrics.confusion_matrix(expected, predicted))
[[41 0 0 0 0 1 0 1 0 0]
[ 0 29 2 0 0 0 0 0 4 2]
[ 0 2 23 0 0 0 1 0 12 0]
[ 0 0 1 38 0 1 0 0 5 1]
[ 0 0 0 0 46 0 2 7 0 0]
[ 0 0 0 0 0 56 1 1 0 1]
[ 0 0 0 0 1 1 43 0 0 0]
[ 0 0 0 0 0 1 0 40 0 0]
[ 0 2 0 0 0 0 0 2 34 0]
[ 0 1 1 1 0 2 1 5 2 35]]
特に、1、2、3、9の数字がしばしば8と表示されていることがわかります。
3.4.4. 教師あり学習: 住宅データの回帰¶
ここでは、回帰問題の簡単な例を示します: 特徴の集合から連続値を学習します。
3.4.4.1. データを見てみよう¶
scikit-learnで利用可能なカリフォルニアの住宅価格セットを使用します。これは、カリフォルニア州の住宅市場の8つの属性と中央値の測定を記録したものです。 問題は: 新市場の価格をその属性から予測できるか?:
>>> from sklearn.datasets import fetch_california_housing
>>> data = fetch_california_housing(as_frame=True)
>>> print(data.data.shape)
(20640, 8)
>>> print(data.target.shape)
(20640,)
データポイントが20000以上あることがわかります。
DESCR 変数には、データセットに関する長い説明があります:
>>> print(data.DESCR)
.. _california_housing_dataset:
California Housing dataset
--------------------------
**Data Set Characteristics:**
:Number of Instances: 20640
:Number of Attributes: 8 numeric, predictive attributes and the target
:Attribute Information:
- MedInc median income in block group
- HouseAge median house age in block group
- AveRooms average number of rooms per household
- AveBedrms average number of bedrooms per household
- Population block group population
- AveOccup average number of household members
- Latitude block group latitude
- Longitude block group longitude
:Missing Attribute Values: None
This dataset was obtained from the StatLib repository.
https://www.dcc.fc.up.pt/~ltorgo/Regression/cal_housing.html
The target variable is the median house value for California districts,
expressed in hundreds of thousands of dollars ($100,000).
This dataset was derived from the 1990 U.S. census, using one row per census
block group. A block group is the smallest geographical unit for which the U.S.
Census Bureau publishes sample data (a block group typically has a population
of 600 to 3,000 people).
A household is a group of people residing within a home. Since the average
number of rooms and bedrooms in this dataset are provided per household, these
columns may take surprisingly large values for block groups with few households
and many empty houses, such as vacation resorts.
It can be downloaded/loaded using the
:func:`sklearn.datasets.fetch_california_housing` function.
.. rubric:: References
- Pace, R. Kelley and Ronald Barry, Sparse Spatial Autoregressions,
Statistics and Probability Letters, 33 (1997) 291-297
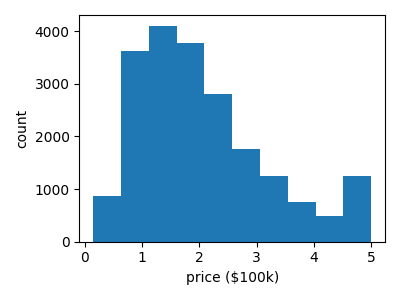
ヒストグラム、散布図、その他のプロットタイプを使ってデータの断片を素早く視覚化することは、しばしば役に立ちます。 matplotlibを使って、目標値のヒストグラムを表示してみましょう: 各地域の中央値:
>>> plt.hist(data.target)
(array([...
私たちの問題に関連する機能があるかどうか、簡単に見てみましょう:
>>> for index, feature_name in enumerate(data.feature_names):
... plt.figure()
... plt.scatter(data.data[feature_name], data.target)
<Figure size...
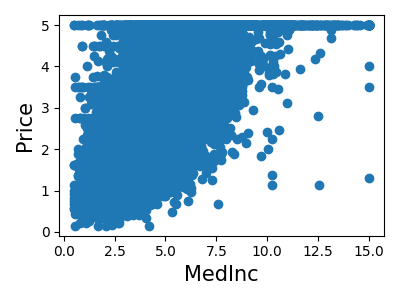
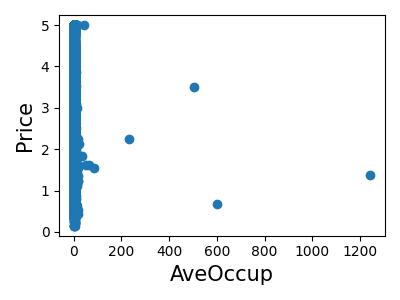
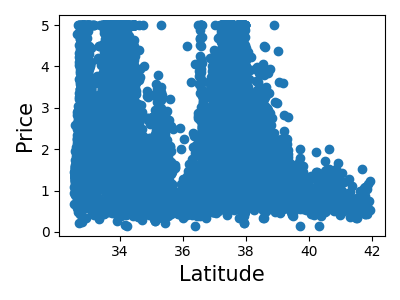
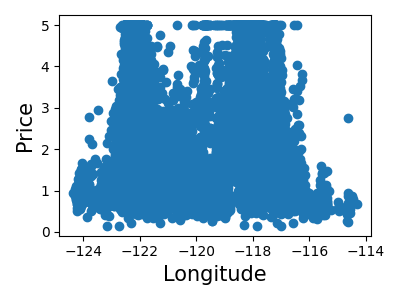
これは、 特徴選択 と呼ばれるテクニックの手動バージョンです。
Tip
機械学習では、特定の問題に対してどの特徴が最も有用かを決定するために、特徴選択を使用することが有用な場合があります。 最も有益な特徴を選択するこの種の作業を定量化する自動化された方法が存在します。
3.4.4.2. 住宅価格の予測: 単回帰¶
では、 scikit-learn を使って住宅データに簡単な線形回帰を行ってみましょう。使用する回帰因子の可能性はたくさんあります。 特に簡単なのは LinearRegression です: これは基本的に、通常の最小二乗計算のラッパーです:
>>> from sklearn.model_selection import train_test_split
>>> X_train, X_test, y_train, y_test = train_test_split(data.data, data.target)
>>> from sklearn.linear_model import LinearRegression
>>> clf = LinearRegression()
>>> clf.fit(X_train, y_train)
LinearRegression()
>>> predicted = clf.predict(X_test)
>>> expected = y_test
>>> print("RMS: %s" % np.sqrt(np.mean((predicted - expected) ** 2)))
RMS: 0.7...
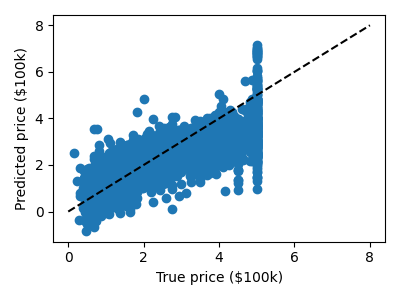
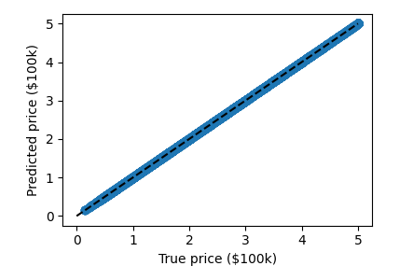
誤差をプロットします: 予測値の関数として期待されます:
>>> plt.scatter(expected, predicted)
<matplotlib.collections.PathCollection object at ...>
Tip
いくつかのバイアスがあるのは明らかですが、予測は少なくとも実際の価格と相関しています。 例えば、真の価格と予測価格の間のRMS残差を計算することで、リグレッサーの性能を評価することが考えられます。しかし、これにはいくつかの微妙な点があり、後のセクションで説明します。
3.4.5. 予測性能の測定¶
3.4.5.1. K-neighbors分類器の簡単なテスト¶
ここでは引き続き数字データを見ていきますが、 K-Neighbors 分類器に切り替えてみましょう。 K-neighbors 分類器は、インスタンスベースの分類器です。 K-neighbors 分類器は、パラメータ空間内の K 個の最も近い点のラベルに基づいて、未知の点のラベルを予測します
>>> # Get the data
>>> from sklearn.datasets import load_digits
>>> digits = load_digits()
>>> X = digits.data
>>> y = digits.target
>>> # Instantiate and train the classifier
>>> from sklearn.neighbors import KNeighborsClassifier
>>> clf = KNeighborsClassifier(n_neighbors=1)
>>> clf.fit(X, y)
KNeighborsClassifier(...)
>>> # Check the results using metrics
>>> from sklearn import metrics
>>> y_pred = clf.predict(X)
>>> print(metrics.confusion_matrix(y_pred, y))
[[178 0 0 0 0 0 0 0 0 0]
[ 0 182 0 0 0 0 0 0 0 0]
[ 0 0 177 0 0 0 0 0 0 0]
[ 0 0 0 183 0 0 0 0 0 0]
[ 0 0 0 0 181 0 0 0 0 0]
[ 0 0 0 0 0 182 0 0 0 0]
[ 0 0 0 0 0 0 181 0 0 0]
[ 0 0 0 0 0 0 0 179 0 0]
[ 0 0 0 0 0 0 0 0 174 0]
[ 0 0 0 0 0 0 0 0 0 180]]
どうやら完璧な分類器を見つけたようです! しかし、これは誤解を招きます: 分類器は基本的に、すでに見たすべてのサンプルを "記憶" します。このアルゴリズムがどれだけ優れているかを本当にテストするには、まだ見た ことのない サンプルを試す必要があります。
この問題は回帰モデルでも起こります。以下では、 "決定木" という別のインスタンスベースのモデルを、先に紹介したカリフォルニア州の住宅価格データセットに当てはめます:
>>> from sklearn.datasets import fetch_california_housing
>>> from sklearn.tree import DecisionTreeRegressor
>>> data = fetch_california_housing(as_frame=True)
>>> clf = DecisionTreeRegressor().fit(data.data, data.target)
>>> predicted = clf.predict(data.data)
>>> expected = data.target
>>> plt.scatter(expected, predicted)
<matplotlib.collections.PathCollection object at ...>
>>> plt.plot([0, 50], [0, 50], '--k')
[<matplotlib.lines.Line2D object at ...]
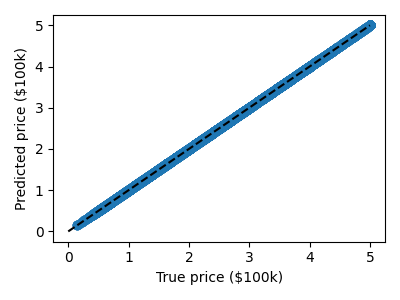
ここでも、モデルはトレーニングセットを完全に記憶することができたため、予測は一見完璧に見えます。
警告
テストセットでのパフォーマンス
テストセットでの性能はオーバーフィットを測定しません (上述の通り)
3.4.5.2. 正しいアプローチ: 検証セットの使用¶
予測関数のパラメータを学習し、それを同じデータでテストするのは方法論的に誤りです: 今見たサンプルのラベルを繰り返すだけのモデルは満点ですが、まだ見たことのないデータに対して有用な予測はできないでしょう。
過学習を避けるために、2つの異なるセットを定義する必要があります:
予測モデルのパラメータを学習するための学習セット X_train, y_train
予測モデルのフィッティングの評価をするための検証セット X_train, y_train
scikit-learn では、このようなランダム分割は train_test_split() 関数で素早く計算できます:
>>> from sklearn import model_selection
>>> X = digits.data
>>> y = digits.target
>>> X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y,
... test_size=0.25, random_state=0)
>>> print("%r, %r, %r" % (X.shape, X_train.shape, X_test.shape))
(1797, 64), (1347, 64), (450, 64)
トレーニングデータで訓練し、テストデータでテストします:
>>> clf = KNeighborsClassifier(n_neighbors=1).fit(X_train, y_train)
>>> y_pred = clf.predict(X_test)
>>> print(metrics.confusion_matrix(y_test, y_pred))
[[37 0 0 0 0 0 0 0 0 0]
[ 0 43 0 0 0 0 0 0 0 0]
[ 0 0 43 1 0 0 0 0 0 0]
[ 0 0 0 45 0 0 0 0 0 0]
[ 0 0 0 0 38 0 0 0 0 0]
[ 0 0 0 0 0 47 0 0 0 1]
[ 0 0 0 0 0 0 52 0 0 0]
[ 0 0 0 0 0 0 0 48 0 0]
[ 0 0 0 0 0 0 0 0 48 0]
[ 0 0 0 1 0 1 0 0 0 45]]
>>> print(metrics.classification_report(y_test, y_pred))
precision recall f1-score support
0 1.00 1.00 1.00 37
1 1.00 1.00 1.00 43
2 1.00 0.98 0.99 44
3 0.96 1.00 0.98 45
4 1.00 1.00 1.00 38
5 0.98 0.98 0.98 48
6 1.00 1.00 1.00 52
7 1.00 1.00 1.00 48
8 1.00 1.00 1.00 48
9 0.98 0.96 0.97 47
accuracy 0.99 450
macro avg 0.99 0.99 0.99 450
weighted avg 0.99 0.99 0.99 450
平均化されたf1スコアは、アルゴリズムの全体的なパフォーマンスを測る便利な尺度としてよく使われます。分類レポートの最下段に表示されます; 直接アクセスすることもできます:
>>> metrics.f1_score(y_test, y_pred, average="macro")
0.991367...
先に見た過学習は、教師データ自体のf1スコアを計算することで定量化できます:
>>> metrics.f1_score(y_train, clf.predict(X_train), average="macro")
1.0
注釈
回帰測定基準 回帰モデルの場合、説明分散のような異なる指標を使う必要があります。
3.4.5.3. 検証によるモデルの選択¶
Tip
ガウスナイーブ、サポートベクターマシン、K近傍法を数字データセットに適用しました。これらの検証ツールが揃ったので、3つの推定量のうちどれがこのデータセットに最適かを定量的に問うことができます。
各推定量にデフォルトのハイパーパラメータを設定した場合、 検証セット で最高のf1スコアを与えるのはどれでしょう? ハイパーパラメータは,分類器をインスタンス化するときに設定されるパラメータです: 例えば、
clf = KNeighborsClassifier(n_neighbors=1)のn_neighbors>>> from sklearn.naive_bayes import GaussianNB >>> from sklearn.neighbors import KNeighborsClassifier >>> from sklearn.svm import LinearSVC >>> X = digits.data >>> y = digits.target >>> X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, ... test_size=0.25, random_state=0) >>> for Model in [GaussianNB(), KNeighborsClassifier(), LinearSVC(dual=False)]: ... clf = Model.fit(X_train, y_train) ... y_pred = clf.predict(X_test) ... print('%s: %s' % ... (Model.__class__.__name__, metrics.f1_score(y_test, y_pred, average="macro"))) GaussianNB: 0.8... KNeighborsClassifier: 0.9... LinearSVC: 0.9...
それぞれの分類器について、どのハイパーパラメータの値が、ディジットのデータに対して最良の結果を与えるでしょうか?
LinearSVCにはloss='l2'とloss='l1'を使います。KNeighborsClassifierには、1から10までのn_neighborsを使います。GaussianNBは調整可能なハイパーパラメータを持っていないことに注意してください。LinearSVC(loss='l1'): 0.930570687535 LinearSVC(loss='l2'): 0.933068826918 ------------------- KNeighbors(n_neighbors=1): 0.991367521884 KNeighbors(n_neighbors=2): 0.984844206884 KNeighbors(n_neighbors=3): 0.986775344954 KNeighbors(n_neighbors=4): 0.980371905382 KNeighbors(n_neighbors=5): 0.980456280495 KNeighbors(n_neighbors=6): 0.975792419414 KNeighbors(n_neighbors=7): 0.978064579214 KNeighbors(n_neighbors=8): 0.978064579214 KNeighbors(n_neighbors=9): 0.978064579214 KNeighbors(n_neighbors=10): 0.975555089773
解答: code source
3.4.5.4. 交差検証¶
交差検証は、 'folds' と呼ばれる訓練セットとテストセットのペアでデータを繰り返し分割することからなります。 Scikit-learnには、これらすべてのフォールドのスコアを自動的に計算する関数が用意されています。 ここではk=5で KFold とします。
>>> clf = KNeighborsClassifier()
>>> from sklearn.model_selection import cross_val_score
>>> cross_val_score(clf, X, y, cv=5)
array([0.947..., 0.955..., 0.966..., 0.980..., 0.963... ])
ランダム分割など、さまざまな分割戦略を用いることができます:
>>> from sklearn.model_selection import ShuffleSplit
>>> cv = ShuffleSplit(n_splits=5)
>>> cross_val_score(clf, X, y, cv=cv)
array([...])
Tip
scikit-learnには 様々な交差検証戦略 が存在します。 これらはしばしば、非同一データセットを考慮するのに有用です。
3.4.5.5. クロスバリデーションによるハイパーパラメータの最適化¶
リッジ回帰 のような正則化線形モデルを考えてみましょう、これはl2正則化を使用しています、また、l1正則化を使用する ラッソ回帰 があります。 正則化パラメータの選択は重要です。
単純な回帰問題である糖尿病データセットにこれらのパラメータを設定してみましょう。 糖尿病データは、442人の患者を対象に測定された10の生理学的変数(年齢、性別、体重、血圧)と、1年後の疾患進行の指標から構成されます:
>>> from sklearn.datasets import load_diabetes
>>> data = load_diabetes()
>>> X, y = data.data, data.target
>>> print(X.shape)
(442, 10)
デフォルトのハイパーパラメータで、交差検証のスコアを計算します:
>>> from sklearn.linear_model import Ridge, Lasso
>>> for Model in [Ridge, Lasso]:
... model = Model()
... print('%s: %s' % (Model.__name__, cross_val_score(model, X, y).mean()))
Ridge: 0.4...
Lasso: 0.3...
基本的なハイパーパラメータ最適化¶
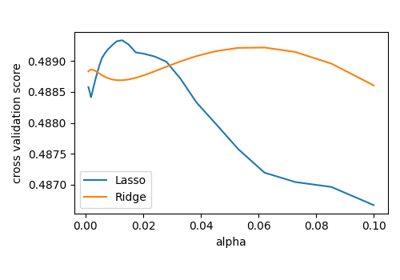
alphaの関数としてクロスバリデーションのスコアを計算します、 Lasso と Ridge の正則化の強さ。0.0001から1の間で20のalpha値を選びます:
>>> alphas = np.logspace(-3, -1, 30)
>>> for Model in [Lasso, Ridge]:
... scores = [cross_val_score(Model(alpha), X, y, cv=3).mean()
... for alpha in alphas]
... plt.plot(alphas, scores, label=Model.__name__)
[<matplotlib.lines.Line2D object at ...
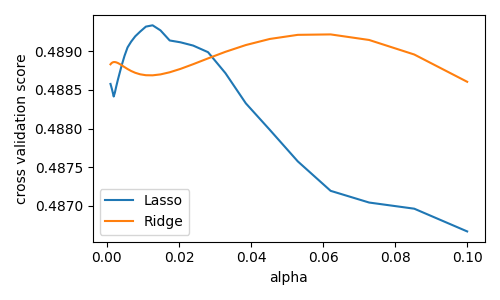
自動的にグリッド検索を行う¶
sklearn.grid_search.GridSearchCV は、推定器と検索するパラメータ値の辞書で構成されます。 最適なパラメータは次のようにして求めることができます:
>>> from sklearn.model_selection import GridSearchCV
>>> for Model in [Ridge, Lasso]:
... gscv = GridSearchCV(Model(), dict(alpha=alphas), cv=3).fit(X, y)
... print('%s: %s' % (Model.__name__, gscv.best_params_))
Ridge: {'alpha': np.float64(0.06210169418915616)}
Lasso: {'alpha': np.float64(0.01268961003167922)}
内蔵ハイパーパラメータ探索¶
scikit-learnのいくつかのモデルでは、交差検証は大規模なデータセットでより効率的に実行できます。 この場合、特定のモデルの交差検証バージョンが含まれます。 Ridge と Lasso の交差検証バージョンはそれぞれ RidgeCV と LassoCV です。これらの推定量に対するパラメータ探索は以下のように行うことができます:
>>> from sklearn.linear_model import RidgeCV, LassoCV
>>> for Model in [RidgeCV, LassoCV]:
... model = Model(alphas=alphas, cv=3).fit(X, y)
... print('%s: %s' % (Model.__name__, model.alpha_))
RidgeCV: 0.0621016941892
LassoCV: 0.0126896100317
GridSearchCV が返す結果と一致することがわかります。
ネストされた交差検証¶
これらの推定量の性能はどのように測定するのでしょうか? ハイパーパラメータを設定するためにデータを使用したので、実際に新しいデータでテストする必要があります。これは、CVオブジェクトに cross_val_score() を実行することで可能になります。ここでは2つの交差検証ループが行われています、 これは '入れ子交差検証' と呼ばれます:
for Model in [RidgeCV, LassoCV]:
scores = cross_val_score(Model(alphas=alphas, cv=3), X, y, cv=3)
print(Model.__name__, np.mean(scores))
3.4.6. 教師なし学習: 次元削減と可視化¶
教師なし学習は、yのないX: つまりラベルのないデータに適用されます。 典型的な使用例は、データの隠れた構造を見つけることです。
3.4.6.1. 次元削減: PCA¶
次元削減は、元の特徴セットよりも小さい新しい人工的な特徴セットを導き出します。ここでは Principal Component Analysis (PCA) とします、 元のデータの分散の大部分を保持しようとする次元削減です。アヤメの花データセットに sklearn.decomposition.PCA を使います:
>>> X = iris.data
>>> y = iris.target
Tip
PCA は、行列Xの切断特異値分解を用いて、元の特徴の線形結合を計算します、 それを使用して、データを上位特異ベクトルの底辺に投影します。
>>> from sklearn.decomposition import PCA
>>> pca = PCA(n_components=2, whiten=True)
>>> pca.fit(X)
PCA(n_components=2, whiten=True)
PCA がフィッティングされると、 components_ 属性の特異ベクトルが表示されます:
>>> pca.components_
array([[ 0.3..., -0.08..., 0.85..., 0.3...],
[ 0.6..., 0.7..., -0.1..., -0.07...]])
その他の属性も利用可能です:
>>> pca.explained_variance_ratio_
array([0.92..., 0.053...])
アヤメの花データセットを最初の2次元に沿って投影してみましょう::
>>> X_pca = pca.transform(X)
>>> X_pca.shape
(150, 2)
PCA normalizes と whitens は、データが単位分散で両成分を中心とすることを意味します:
>>> X_pca.mean(axis=0)
array([...e-15, ...e-15])
>>> X_pca.std(axis=0, ddof=1)
array([1., 1.])
さらに、サンプル成分はもはや線形相関を持ちません:
>>> np.corrcoef(X_pca.T)
array([[1.00000000e+00, 0.0],
[0.0, 1.00000000e+00]])
保持される成分の数が2または3である場合、PCAはデータセットを視覚化するのに有効です:
>>> target_ids = range(len(iris.target_names))
>>> for i, c, label in zip(target_ids, 'rgbcmykw', iris.target_names):
... plt.scatter(X_pca[y == i, 0], X_pca[y == i, 1],
... c=c, label=label)
<matplotlib.collections.PathCollection ...
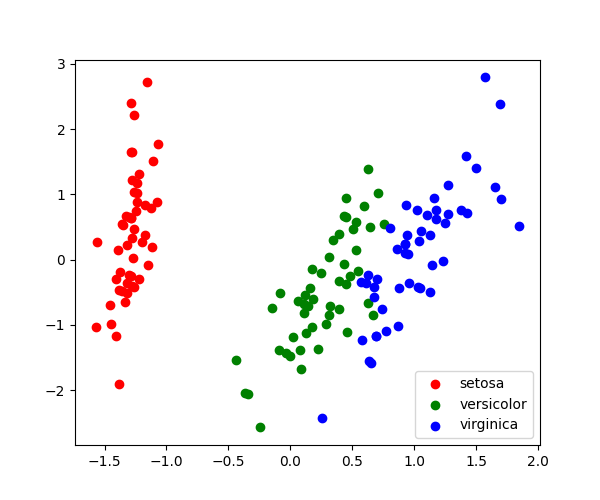
Tip
なお、この投影は、(色で表される)ラベルに関するいかなる情報も 持たず に決定されました: これは、学習が 教師なし であるという意味です。 とはいえ、投影によって、パラメータ空間におけるさまざまな花の分布を知ることができます: 特に、 iris setosa は他の2種よりもはるかにはっきりしています。
3.4.6.2. 非線形埋め込みによる可視化: tSNE¶
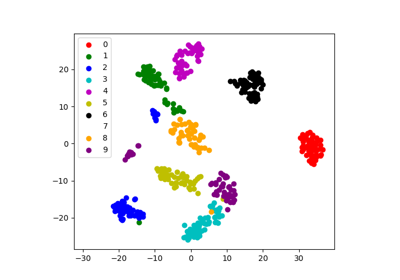
視覚化には、より複雑な埋め込みが有効です (統計分析では、コントロールが難しくなります)。 sklearn.manifold.TSNE はそのような強力な多様体学習法です。 数字は 8*8=64 次元のベクトルなので、これを 数字 データセットに適用します。 2Dに埋め込むことで視覚化が可能になります:
>>> # Take the first 500 data points: it's hard to see 1500 points
>>> X = digits.data[:500]
>>> y = digits.target[:500]
>>> # Fit and transform with a TSNE
>>> from sklearn.manifold import TSNE
>>> tsne = TSNE(n_components=2, learning_rate='auto', init='random', random_state=0)
>>> X_2d = tsne.fit_transform(X)
>>> # Visualize the data
>>> plt.scatter(X_2d[:, 0], X_2d[:, 1], c=y)
<matplotlib.collections.PathCollection object at ...>
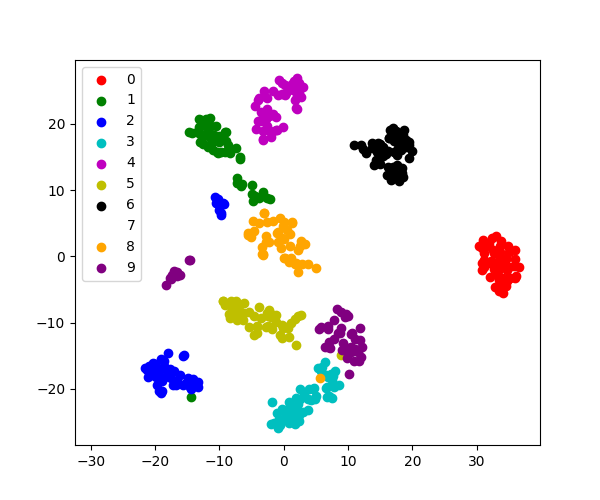
sklearn.manifold.TSNE は、クラス情報にアクセスできなかったにもかかわらず、数字の異なるクラスを非常にうまく分離しました。
3.4.7. パラメータの選択、検証、テスト¶
3.4.7.1. ハイパーパラメータ、オーバーフィット、アンダーフィット¶
参考
このセクションは Andrew Ng's excellent Coursera course からの抜粋です
バリデーションとクロスバリデーションに関連する問題は機械学習の実践における最も重要な側面のいくつかです。データに最適なモデルを選択することが重要です、 これは、機械学習の専門家にはあまり理解されていない問題の一部です。
中心的な問題は: エスティメーターのパフォーマンスが低い場合、どのように前進すべきでしょうか?
よりシンプルなモデルを使うか、より複雑なモデルを使うか?
観測された各データポイントにさらに特徴を加えるのか?
トレーニングサンプルを増やす?
その答えはしばしば直感に反します。 特に、 より複雑なモデルを使うと、結果が悪くなることがあります。 また、 トレーニングデータを追加しても結果が改善しないこともあります。 どのようなステップを踏めばモデルが改善されるかを判断する能力が、機械学習の成功者と失敗者を分けるのです。
バイアスと分散のトレードオフ: 単純回帰問題のイラスト¶
簡単な1次元回帰問題から始めましょう。これにより、データとモデルを簡単に視覚化することができ、結果は高次元のデータセットにも簡単に一般化できます。 単純な 線形回帰 問題を sklearn.linear_model で探ってみます。
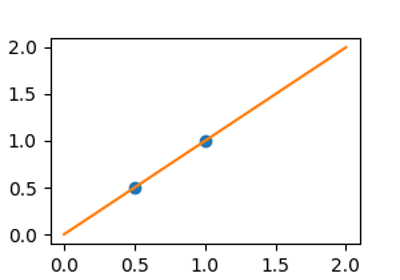
X = np.c_[0.5, 1].T
y = [0.5, 1]
X_test = np.c_[0, 2].T
ノイズがなければ、線形回帰はデータに完全にフィットします。
from sklearn import linear_model
regr = linear_model.LinearRegression()
regr.fit(X, y)
plt.plot(X, y, "o")
plt.plot(X_test, regr.predict(X_test))
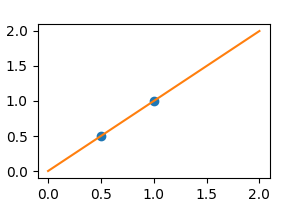
[<matplotlib.lines.Line2D object at 0x7b2074693ce0>]
現実の状況では、データにノイズ (例えば測定ノイズなど) が含まれます:
rng = np.random.default_rng(27446968)
for _ in range(6):
noisy_X = X + np.random.normal(loc=0, scale=0.1, size=X.shape)
plt.plot(noisy_X, y, "o")
regr.fit(noisy_X, y)
plt.plot(X_test, regr.predict(X_test))
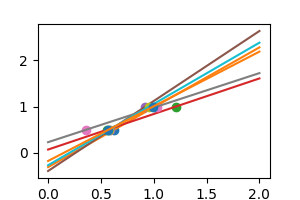
見てわかるように、この線形モデルはデータのノイズをとらえ、増幅しています。 多くの分散を表示しています。
正則化を用いる別の線形推定器、 Ridge 推定器を用いることができます。 この推定量は、非常に高い相関は多くの場合あやしいという仮定の下で、係数をゼロに縮小することによって正則化します。alphaパラメータは、使用する収縮量を制御します。
regr = linear_model.Ridge(alpha=0.1)
np.random.seed(0)
for _ in range(6):
noisy_X = X + np.random.normal(loc=0, scale=0.1, size=X.shape)
plt.plot(noisy_X, y, "o")
regr.fit(noisy_X, y)
plt.plot(X_test, regr.predict(X_test))
plt.show()
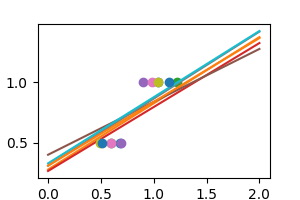
見てわかるように、この推定量では分散がかなり小さくなっています。 しかし、系統的に係数を過小評価します。 これは偏った振る舞いを示します。
これは、 バイアスとばらつきのトレードオフ の典型的な例です: 非正規化推定量は偏っていませんが、多くの分散を示すことがあります。 高正則化モデルは分散は少ないですがバイアスは大きいです。 このバイアスは必ずしも悪いことではありません: 重要なのは、最良の予測性能をもたらすバイアスと分散のトレードオフを選択することです。 特定のデータセットには、そのデータがサポートできる最高の複雑さに対応するスイートスポットがあります、そしてそれは利用可能なノイズと観測の量に依存します。
3.4.7.2. バイアスとバリアンスのトレードオフの可視化¶
Tip
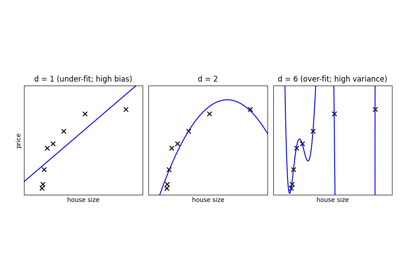
特定のデータセットとモデル (たとえば多項式) が与えられている場合、予測精度を制限しているのがバイアス (アンダーフィット) かバリアンスかを理解し、最適な予測を得るために ハイパーパラメータ (ここでは多項式の次数 d ) をどのように調整すればよいかを検討します。
与えられたデータについて、次数の異なる単純な多項回帰モデルを当てはめてみましょう:
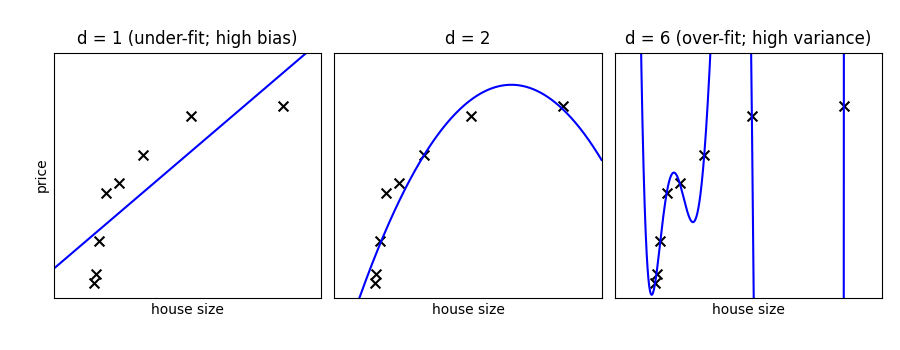
Tip
上の図では、3つの異なる d の値に対するフィッティング結果を示しています。d = 1 の場合、データはアンダーフィットされています。これは、モデルが単純すぎることを意味します。どんな直線を引いても、このデータにはうまくフィットしません。このような場合、モデルは高いバイアスを持つと言います。モデル自体が偏っており、その結果としてデータにうまく当てはまらないのです。反対に、 d = 6 の場合はオーバーフィットしています。これは、モデルが持つ自由度 (この場合は6) が多すぎて、訓練データには完全に一致するものの、新しいデータ点を追加した場合、その点がこの次数-6の曲線から大きく外れてしまう可能性が高いということです。このような場合、モデルは 高いバリアンス を持つと言います。 "高いバリアンス" とは、入力データのわずかな変化によって、モデルの予測が大きく変わってしまうことを意味しています。
In the middle, for d = 2, we have found a good mid-point. It fits
the data fairly well, and does not suffer from the bias and variance
problems seen in the figures on either side. What we would like is a way
to quantitatively identify bias and variance, and optimize the
metaparameters (in this case, the polynomial degree d) in order to
determine the best algorithm.
検証曲線¶
上の例のようなデータセットを作ってみましょう:
>>> def generating_func(x, rng, err=0.5):
... return rng.normal(10 - 1. / (x + 0.1), err)
>>> # randomly sample more data
>>> rng = np.random.default_rng(27446968)
>>> x = rng.random(size=200)
>>> y = generating_func(x, err=1., rng=rng)
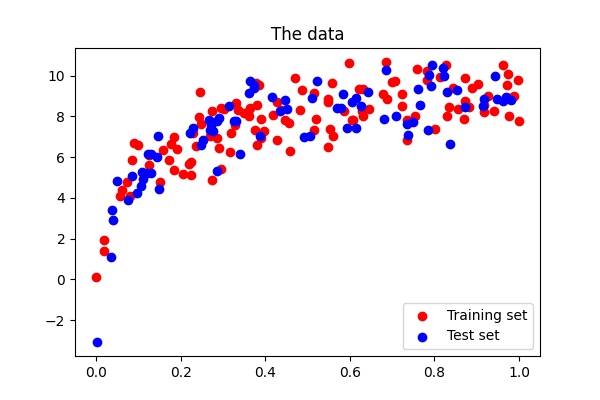
モデルのバイアスと分散を定量化する中心的な方法は、 test data に適用することです、列車と同じ分布からサンプリングされますが、独立したノイズを捕捉します:
>>> xtrain, xtest, ytrain, ytest = train_test_split(x, y, test_size=0.4)
検証曲線 検証曲線は、複雑さを制御するモデルのパラメータを変化させることで構成されます (ここでは多項式の次数) そして、訓練データ、およびテストデータ (例 クロスバリデーション) に対するモデルの誤差を測定します. 次に、テスト誤差が最小になるようにモデルパラメータを調整します:
sklearn.model_selection.validation_curve() を使って訓練誤差とテスト誤差を計算し、それをプロットします:
>>> from sklearn.model_selection import validation_curve
>>> degrees = np.arange(1, 21)
>>> model = make_pipeline(PolynomialFeatures(), LinearRegression())
>>> # Vary the "degrees" on the pipeline step "polynomialfeatures"
>>> train_scores, validation_scores = validation_curve(
... model, x[:, np.newaxis], y,
... param_name='polynomialfeatures__degree',
... param_range=degrees)
>>> # Plot the mean train score and validation score across folds
>>> plt.plot(degrees, validation_scores.mean(axis=1), label='cross-validation')
[<matplotlib.lines.Line2D object at ...>]
>>> plt.plot(degrees, train_scores.mean(axis=1), label='training')
[<matplotlib.lines.Line2D object at ...>]
>>> plt.legend(loc='best')
<matplotlib.legend.Legend object at ...>
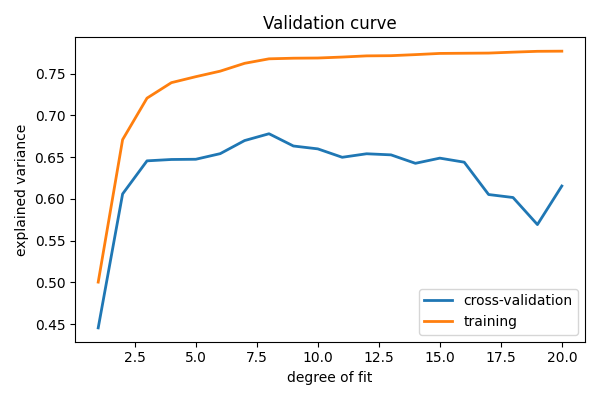
この図は、なぜ検証が重要なのかを示しています。プロットの左側には、非常に次数の低い多項式があり、データにフィットしていません。このため、訓練セットと検証セットの両方で、説明される分散が低くなります。 プロットの右端には、非常に次数の高い多項式があり、データにオーバーフィットしています。これは、トレーニングの説明済み分散が非常に高いのに対して、検証セットでは低いことからもわかります。 d の4、5番あたりを選べば、最高のトレードオフが得られます。
Tip
The astute reader will realize that something is amiss here: in the
above plot, d = 4 gives the best results. But in the previous plot,
we found that d = 6 vastly over-fits the data. What’s going on here?
The difference is the number of training points used. In the
previous example, there were only eight training points. In this
example, we have 100. As a general rule of thumb, the more training
points used, the more complicated model can be used. But how can you
determine for a given model whether more training points will be
helpful? A useful diagnostic for this are learning curves.
学習曲線¶
学習曲線は、訓練点と検証点の数の関数として訓練点と検証点のスコアを示します。訓練データのサブセットで訓練する場合、訓練スコアは完全な訓練セットではなく、このサブセットを使用して計算されることに注意してください。この曲線は、学習サンプルを追加することがどれだけ有益かを定量的に示しています。
scikit-learn は sklearn.model_selection.learning_curve() を提供します:
>>> from sklearn.model_selection import learning_curve
>>> train_sizes, train_scores, validation_scores = learning_curve(
... model, x[:, np.newaxis], y, train_sizes=np.logspace(-1, 0, 20))
>>> # Plot the mean train score and validation score across folds
>>> plt.plot(train_sizes, validation_scores.mean(axis=1), label='cross-validation')
[<matplotlib.lines.Line2D object at ...>]
>>> plt.plot(train_sizes, train_scores.mean(axis=1), label='training')
[<matplotlib.lines.Line2D object at ...>]
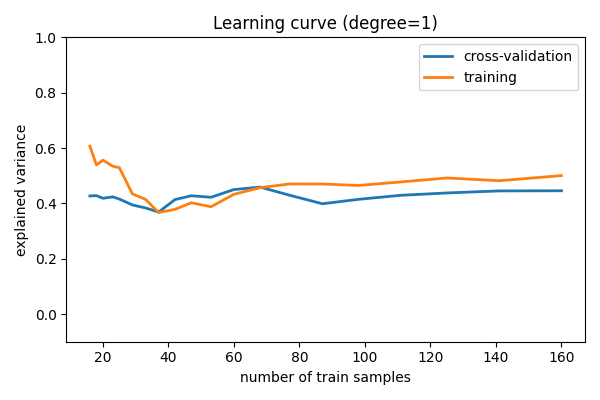
degree=1 モデルの場合¶
検証スコアは訓練セットが大きくなるにつれて 一般的に増加 し、訓練スコアは訓練セットが大きくなるにつれて 一般的に減少 することに注意してください。訓練サイズが大きくなるにつれて、それらは単一の値に収束します。
以上の議論から、 d = 1 はデータにフィットしない高バイアス推定量であることがわかります。これは、トレーニングスコアと検証スコアの両方が低いという事実が示しています。 このような学習曲線に直面したとき、トレーニングデータを増やしても、何の役にも立たないことが予想されます: どちらの線も比較的低いスコアに収束します。
学習曲線が低いスコアに収束したとき、バイアスの高いモデルとなります。
高バイアスモデルは、次のようにして改善できます:
より洗練されたモデルの使用 (つまり、この場合は
dを増やします)各サンプルについて、より多くの特徴を集めます。
正則化モデルの正則化を減らします。
しかし、サンプル数を増やしても、高バイアスモデルは改善されません。
次に、高バリアンス (つまりオーバーフィット) モデルを見てみましょう:
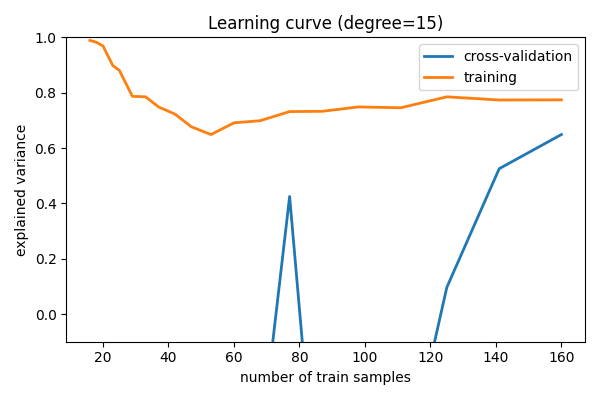
degree=15 モデルの場合¶
ここでは、 d = 15 の学習曲線を示します。 上記の議論から、d = 15 はデータに オーバーフィット する 高分散 推定器であることがわかります。 これは、トレーニングスコアが検証スコアよりもはるかに高いという事実が示しています。 このトレーニングセットにさらにサンプルを追加すると、トレーニングスコアは減少し続け、クロスバリデーション誤差は増加し続け、両者が中間で出会うまで続きます。
全トレーニングセットでまだ収束していない学習曲線は、高バリアンスでオーバーフィットのモデルを示しています。
高バリアンスモデルは、次のようにして改善できます:
より多くのトレーニングサンプルを集めます。
あまり洗練されていないモデルの使用 (つまり、この場合は
dを小さくします)正則化を進めます。
特に、各サンプルについてより多くの特徴を集めても、結果の役には立ちません。
3.4.7.3. モデル選択に関するまとめ¶
アルゴリズムが十分に機能していない原因として、次の2つが考えられることは前述したとおりです: 高いバイアス(アンダーフィット) と高い分散 (オーバーフィット)です。 我々のアルゴリズムを評価するために、トレーニングデータの一部をクロスバリデーション用に確保しました。 学習曲線のテクニックを使えば、データの部分集合を徐々に大きくして訓練し、訓練誤差と交差検証誤差を評価して、アルゴリズムが高分散か高バイアスかを判断することができます。 しかし、この情報をどうするのでしょうか?
高いバイアス¶
モデルが高い バイアス を示した場合、以下の対処が役立つかもしれません:
より多くの機能を追加します 。住宅価格を予測する例で言えば、その家がある地域、 家が建てられた年、土地の広さなどなどの情報を活用することが役に立つかもしれません。これらの特徴をトレーニングセットとテストセットに加えることで、高バイアス推定量を改善することができます。
より洗練されたモデルを使います 。 モデルに複雑さを加えることで、バイアスを改善することができます。 多項式フィットの場合、次数dを大きくすることで達成できます。 それぞれの学習技術には、複雑さを加える独自の方法があります。
サンプル数を減らします 。 これは分類を改善するものではありませんが、ハイバイアスアルゴリズムは、より少ない訓練サンプルでほぼ同じ誤差を達成することができます。 計算コストの高いアルゴリズムでは、学習サンプルサイズを小さくすることで、スピードが非常に大きく向上することがあります。
正則化を減らします 。正則化は、パラメータの特性に依存するペナルティ項を追加することによって、いくつかの機械学習モデルに単純さを課すために使用されるテクニックです。 モデルのバイアスが大きい場合は、正則化の効果を小さくすることで、より良い結果を得ることができます。
高分散¶
モデルが高い 分散 を示した場合、以下の対処が役立つかもしれません:
少ない機能を使います。 特徴選択テクニックを使うことは有効で、推定値のオーバーフィッティングを減らすことができます。
よりシンプルなモデルを使います 。モデルの複雑さとオーバーフィッティングは密接に関係しています。
より多くのトレーニングサンプルを使用します 。 学習サンプルを追加することで、オーバーフィッティングの影響を軽減し、高分散推定量の改善につながります。
レギュラー化します 。正則化はオーバーフィッティングを防ぐために設計されています。 高分散モデルでは、正則化を進めるとより良い結果が得られます。
このような選択は、実社会では非常に重要になります。 例えば、望遠鏡の使用時間が限られているため、天文学者は多数の天体を観測することと、各天体について多数の特徴を観測することのバランスを追求しなければなりません。特定の学習課題にとってどちらが重要かを判断することで、天文学者が採用する観測戦略に反映させることができます。
3.4.7.4. 最後に一言: 検証セットとテストセットの分離¶
ハイパーパラメータを決定するために検証スキームを使用することは、特定の検証セットにハイパーパラメータをフィットさせることを意味します。パラメータが訓練セットにオーバーフィットすることがあるのと同じように、ハイパーパラメータも検証セットにオーバーフィットすることがあります。このため、検証誤差は新しいデータの分類誤差を過小予測する傾向があります。
このため、データを3つのセットに分けることが推奨されます:
モデルの学習に使用される 学習セット (通常 ~60%のデータ)
モデルの検証に使用される 検証セット (通常 ~20%のデータ)
検証済みモデルの期待誤差を評価するための テストセット (通常 ~20%のデータ)
多くの機械学習の専門家は、テストセットと検証セットを分けていません。 しかし、未知のデータに対するモデルの誤差を測定することが目的であれば、独立したテストセットの使用は不可欠です。
3.4.8. scikit-learnの章の例¶

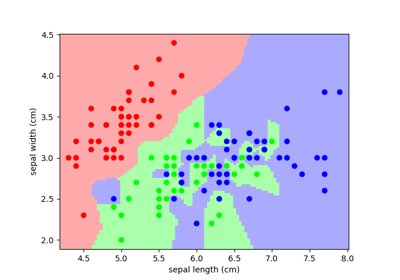


Gallery generated by Sphinx-Gallery
参考
Going further
documentation of scikit-learn は非常に完成度が高く、教訓的です。
Introduction to Machine Learning with Python, by Sarah Guido, Andreas Müller (notebooks available here).